お知らせ:この記事はJLCPCBの提供でお送りしています。

NT金沢への参加等もありESP32+FPGAオーディオ基板の紹介記事が長らく途切れていましたが、この基板を構成する最後の主要パーツであるFPGA上の実装について紹介したいと思います。ちょっと長くなりそうなので、今回はまずFPGA内部の全体構成について紹介します。
基板全体の構成
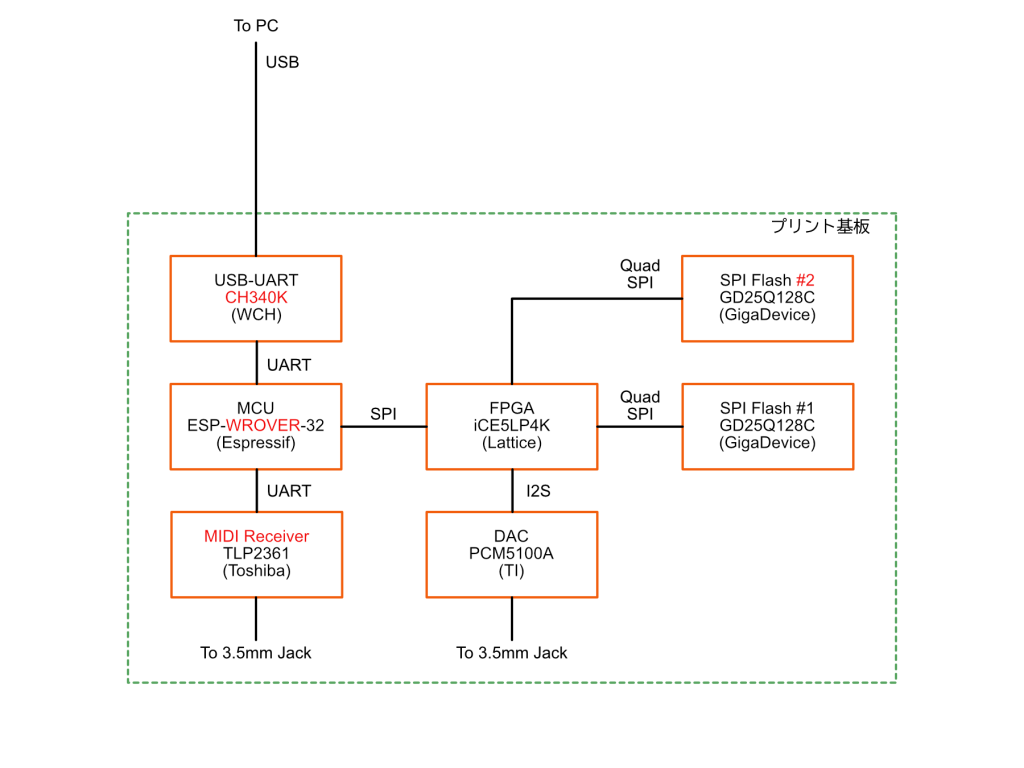
まずはこの基板の全体のブロック図からおさらいしましょう。この基板では音を出力するDACと出力する音のもととなるサンプルデータを記憶しておくSPI FlashがFPGAに接続される構成になっていて、PCM音源のキモとなるSPI Flashからサンプルデータを読み出し、加工してDACに出力する一連の処理はFPGA側で完結しています。MCUであるESP-WROVER-32側では、前回紹介したように音を生成する処理はせず、FPGAのコンフィギュレーションやMIDI信号の解釈、FPGAへのコマンド発行を担当しています。
FPGA内部の構成
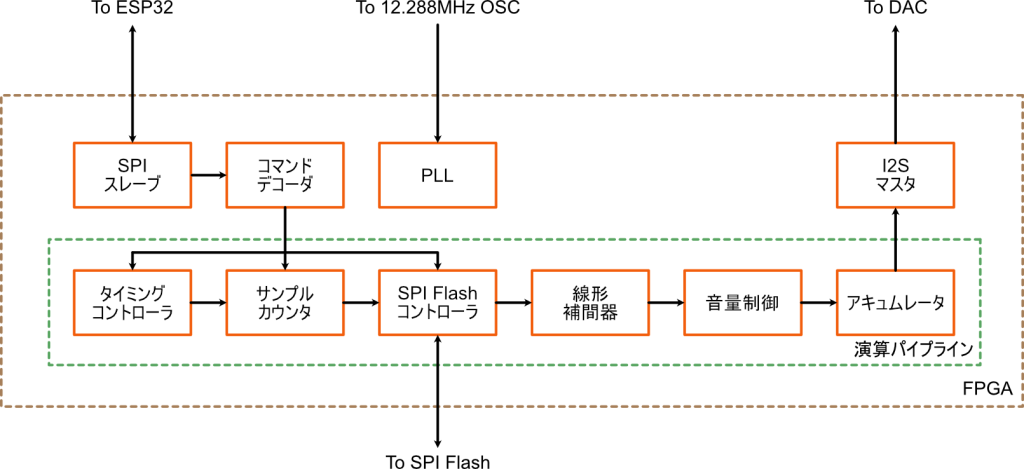
次に、その音源のキモの部分が実装されているFPGAの内部のブロック図を見ていきます。現在の実装では、
- ESP32からのコマンドを受信するためのSPIスレーブ
- 受信したコマンドを解釈するコマンドデコーダ
- コマンドに従って音データを生成する演算パイプライン
- 音データをDACに送信するI2Sマスタ
をFPGA内に実装しています。そのほか、FPGAに内蔵されているPLL 1を使って、各回路ブロックに入力クロックの12.288MHzの4倍の49.152MHzを供給しています。今回使っているFPGAであるiCE40 UltraPlusは低消費電力にフォーカスしたFPGAで、そこまで速く動作するFPGAではないので、動作周波数はこのくらいが限界となりそうです。2Tang Nano 9Kに載っているGOWINのFPGAや、MAX10等々、あるいはもっといいFPGAを使えばもう少し高速に動かせると思います。
なお、今回の回路はすべてSystemVerilogで記述しました。普通のVerilog HDLよりもenumやlogicがあったりとちょっと便利です。
演算パイプライン
第2回でも紹介しましたが、今回制作しているPCM音源は同時に16音を発音できる仕様となっています。今回は内部の回路を自由に記述できるLSIであるFPGAを使っているので、ソフトウェアで処理するときのように各音を逐次処理するのではなく、パイプライン方式を採用し、専用の演算パイプラインで各音の処理を並列に実行しています。
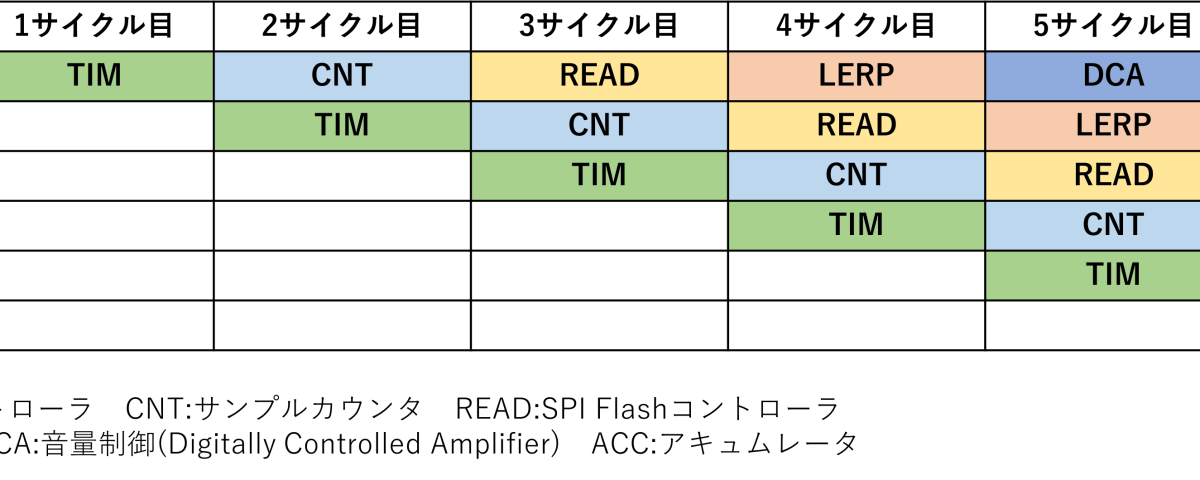
パイプライン方式は一連の処理をいくつかのステップに分割して、各ステップを並列に動作させる考え方です。今回のPCM音源では音を生成する処理を、先ほどのブロック図の「演算パイプライン」セクションに示した6つの処理に分割しています。次の図は、演算パイプライン内で1個目(Slot #0)~6個目(Slot #5)までの音がどのように処理されるかを示した図です。
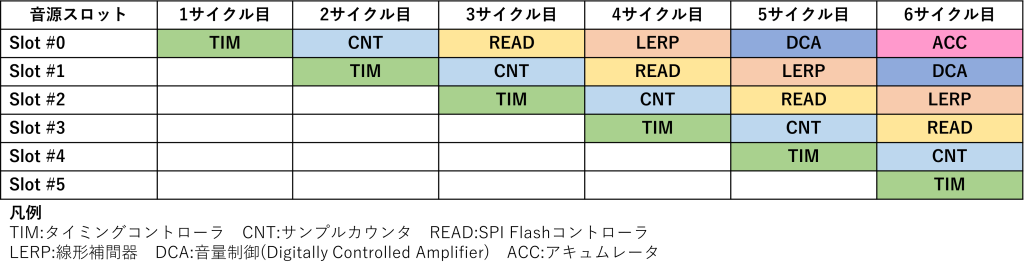
左端の「音源スロット」は1音につき1つ割り当てられる処理単位です。今回は最大で16音同時に発音するので、#0から#15までの16個のスロットがあることになります。この16個のスロットの処理をすべて終えて、その結果を足し合わせた値が最終的にDACに送り込まれ、音として再生されます。今回はこの16スロット分の処理を、演算パイプライン内で並列して行います。並列に行うといっても、タイミングコントローラやサンプルカウンタなどの各回路ブロックは1つずつしか存在しないので、各スロットの処理開始のタイミングをずらし、各スロットの処理においてある回路ブロックが必要となるタイミングが重ならないようにして処理を行います。
例えば、上の図のSlot #0の行を見ると、1サイクル目はTIM(タイミングコントローラ)、2サイクル目はCNT(サンプルカウンタ)の処理が行われています。一方、Slot #1の行を見てみると、2サイクル目にTIMの処理が行われています。同じように、3サイクル目では、Slot #0~2に対して、それぞれ、READ(SPI Flashコントローラ)、CNT、TIMの処理が行われています。つまり、3サイクル目では3つのスロットに対する処理が並列して行われていることになります。6サイクル目になると、ACC~TIMのすべての回路ブロックがいずれかのスロットの処理を実行している状況になり、6個の回路ブロックが並列動作している状態となります。このように、それぞれの回路ブロックが並列に処理をこなしていくのがパイプライン方式です。自動車などの製造ラインをイメージしてみてもわかりやすいかもしれません。
パイプライン方式はCPUの中で命令を実行する際に使われる命令パイプラインとしてよく使われます。CPUでは各音源スロットの処理の代わりに、複数の命令の処理を並列に行うことになります。しかし、CPUの命令の場合、前後の命令間に依存関係が存在する場合があります。例えば、1つ目の命令がA+Bの結果をCに代入する命令で、それに続く2つ目の命令がC+Dの結果をEに代入する命令だった場合、1つ目の命令によって計算結果がCに代入されるまで待たないと、2つ目の命令の計算結果が間違ったものになってしまいます。そのためCPUの命令パイプラインでは依存関係が解消されるまで次のステップに進むのを待ったり、計算結果を先取りしたりといった工夫(フォワーディング)を行ったりします。
一方、今回のPCM音源では、それぞれの音源スロットの間に依存関係は存在しないので、CPUの命令パイプラインに見られるような配慮は必要なく、ある種教科書通りのシンプルなパイプラインとなっています。ただし、CPUの場合はパイプラインの図に示す各サイクルが典型的には1クロック単位となるように設計されますが、PCM音源の演算パイプラインではSPI Flashコントローラが1回の処理に複数クロックを必要とするため、複数クロックで1サイクルとなるように構成しています。
まとめ
今回はESP32+FPGAオーディオ基板のFPGA上に実装しているPCM音源の構成について説明しました。パイプラインによる並列処理はソフトウェアで処理を実装する場合とはちょっと違うアプローチですが、ハードウェアを自由に構成できるFPGAらしい設計といえるのではないかと思います。次回は演算パイプラインの中身を中心に、FPGA側に実装した回路ブロックそれぞれについて説明します。お楽しみに!