
お知らせ:この記事はJLCPCBの提供でお送りしています。
みなさんこんにちは。「ボイスチェンジャーメガホンを作る:原理編」に続いて、ソフトウェア編です。
前回の記事でボイスチェンジャーとして使われるエフェクトをいくつか紹介してきましたが、ボイスチェンジャーメガホンでは、処理の負荷の量やテレビ番組等で使われるボイスチェンジャーエフェクトのような「それっぽさ」の観点から、リサンプリングによるボイスチェンジャーエフェクトを採用しています。今回の記事では、ボイスチェンジャーメガホンに採用したリサンプリングによるピッチシフトの実装の詳細について説明し、次にESP32上にそれを実装するためのポイントについて紹介します。
リサンプリングによるピッチシフト
音声波形の「つぎはぎ」
まず最初に、前回紹介したリサンプリングによるピッチシフトの概念図を再掲します。
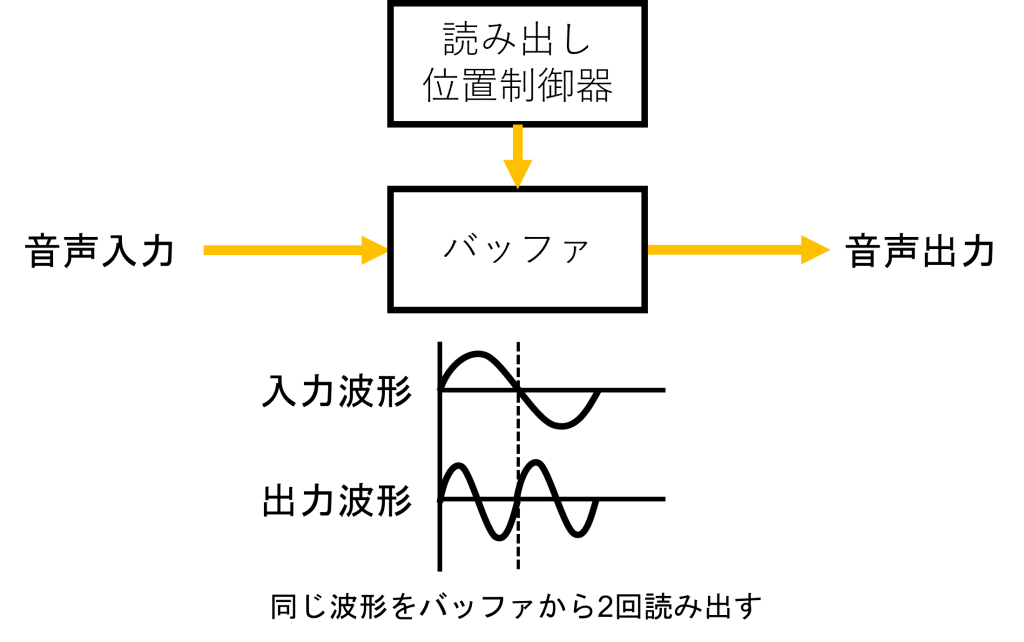
上の図にあるようにリサンプリング方式のピッチシフトでは元の音声を一度バッファに貯めて、それを読み出す速度を加減することでピッチの変更を実現しています。これだけ書くとシンプルなのですが、原理編にも書いたように実際には読み出し速度を加減することに伴ってちょっとした工夫が必要になります。まずは音程を高くするケースを考えてみましょう。
例えば音程を2倍の高さにする場合、再生速度を2倍にする必要があります。再生速度を2倍にしてもデータがバッファに書き込まれる速度は変わりませんから、バッファにある程度データが書き込まれてから再生を開始するといった工夫をしても、いずれどこかの時点でバッファに書き込まれたデータが尽きてしまい読み出せるデータが存在しない瞬間が来ます。通常のデータ通信などではそのような状態が起きてしまった場合、新たなデータが書き込まれるのを待つといった対応が必要になりますが、リアルタイムに動かしているオーディオエフェクトでは新たなデータを待つわけにはいきません。例えば、新たなデータを待っている間を無音にしてしまうと音がぶつぶつと途切れるような状態になってしまいます。
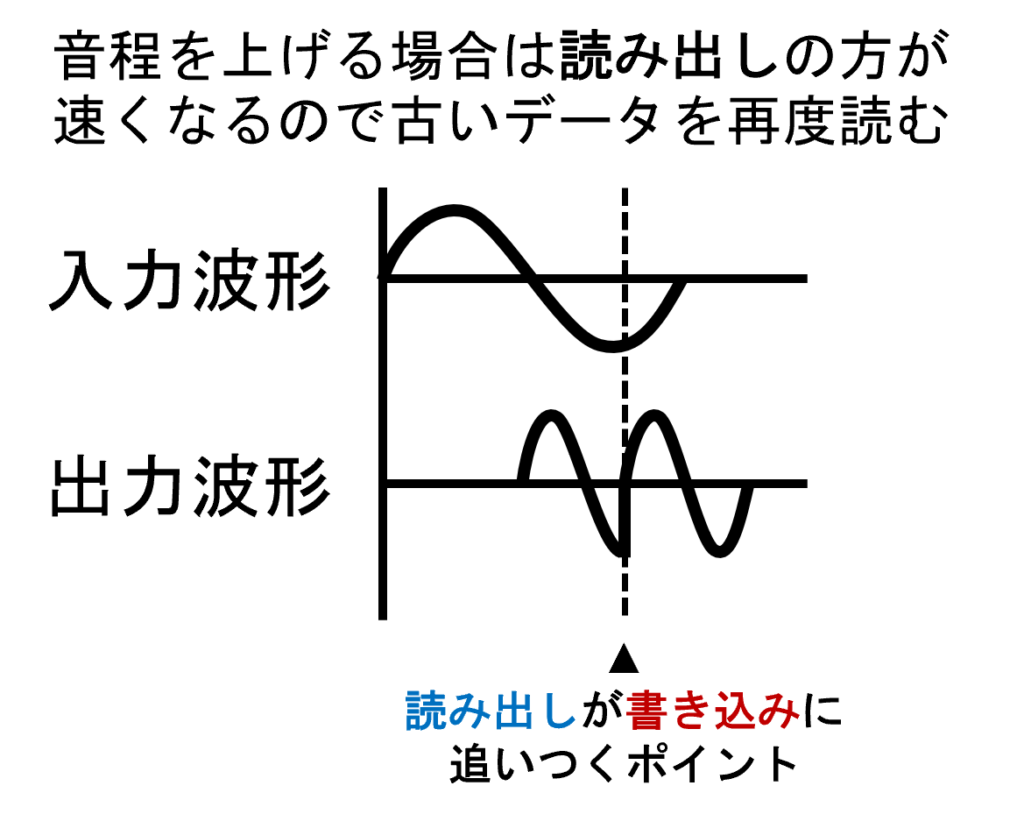
そこで、「それっぽく」つじつまを合わせるために、読み出せるデータがなくなってしまった場合古いデータから再度読み出しを開始します。人間の声の変化の速度は比較的緩やかで、似たような波形の信号が何周期も続くことが多いです。そのため古いデータを持ってきてつぎはぎしても、似たような波形同士のつぎはぎとなり意外とそれっぽく聞こえてしまいます。
ちなみに、ここで出てきた「一番新しいデータまで読んだら次に一番古いデータに読み出す」というのは、バッファの先頭と末尾がつながった状態、要するにリングバッファとしてバッファを実装してやることで容易に実現できます。
次に音程を低くするケースです。音程を高くするときと同じ要領で、音程を1/2にするためには再生速度を1/2にする必要があります。そうなると、今度は読み出し速度よりも書き込み速度の方が速くなってしまいます。無限にメモリがあればどんどん書き込まれるデータをバッファしていき、後を追ってゆっくりデータを読み出せばいいのですが、実際にはメモリは有限なのでバッファの長さも有限になります。そうすると、バッファが満杯になった時にはすでに書かれているデータを捨てて書き込むスペースを確保するしかありません。
バッファをリングバッファとして実装しているとすると、バッファが満杯になった後、最も古いデータを削除して新しいデータで置き換える操作は自動的に実現できます。そのようにして、読み出し速度よりも速い速度で書き込みが進んでいくと、いずれリングバッファ上で読み出し位置を書き込み位置が追い抜かす(周回遅れのようなイメージですね)瞬間がやってきます。
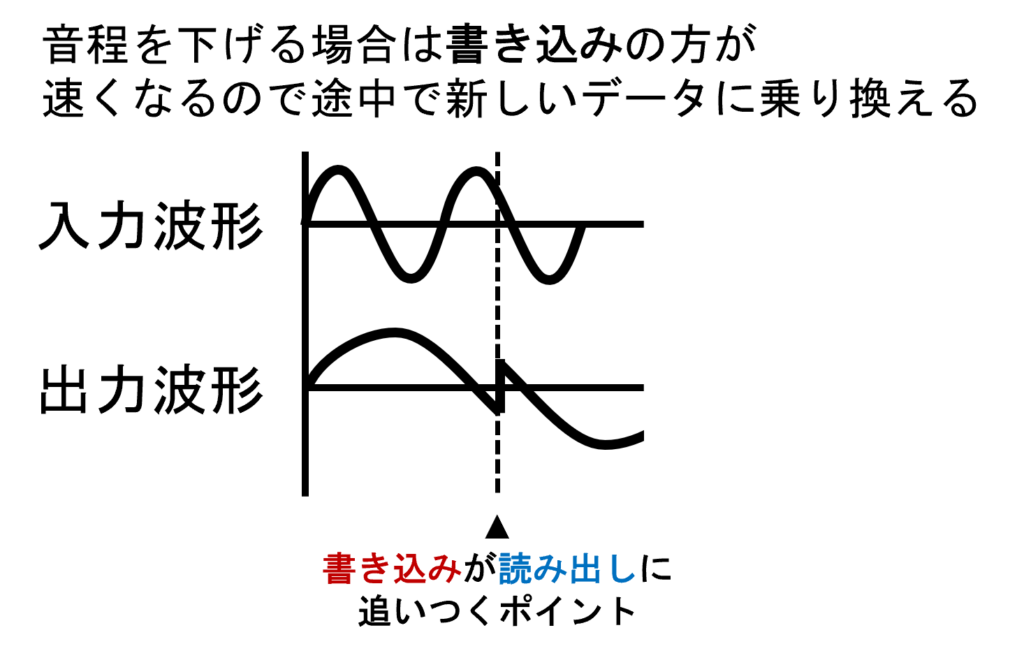
結果として、その瞬間から読み出し側は新しく書かれたデータを読み出すことになり、古いデータから新しいデータに乗り換えたような状態になります。この場合も音程を上げる処理と同様、データののつぎはぎが行われても似たような波形同士のつぎはぎとなるため、それっぽく聞こえてしまうというわけです。
「継ぎ目」を目立たなくする
さて、ここまで、音声データのつぎはぎをしても意外とそれっぽく聞こえてしまうと書いてきましたが、さすがに全く何もしなくてもよいかというとそういうわけではありません。
![]()
音声データをつぎはぎすると、たいていの場合は継ぎ目のポイントが不連続な波形になります。1音声の場合、不連続なポイントは「プツッ」というようなノイズとして聞こえてしまいます。このノイズを抑えるために、継ぎ目の直前で徐々に音量を下げ、継ぎ目のポイントは音量0、継ぎ目を過ぎてから音量を徐々にもとに戻していくという「フェードアウト・フェードイン」処理を行います。前回の記事で紹介したリサンプリングによるピッチシフト処理のサンプル音声では、すでにこの処理が適用されています。以下に、この処理を適用していないサンプルと、適用したサンプル(前回の再掲)を示します。「継ぎ目対策あり」の方では、周期的なプツプツ音がなくなっているのが分かるかと思います。
継ぎ目対策なし
(生成に使ったPythonコードはこちら:pitch_shift_resample_wo_crossfade.py)
継ぎ目対策あり
(生成に使ったPythonコードはこちら:pitch_shift_resample.py)
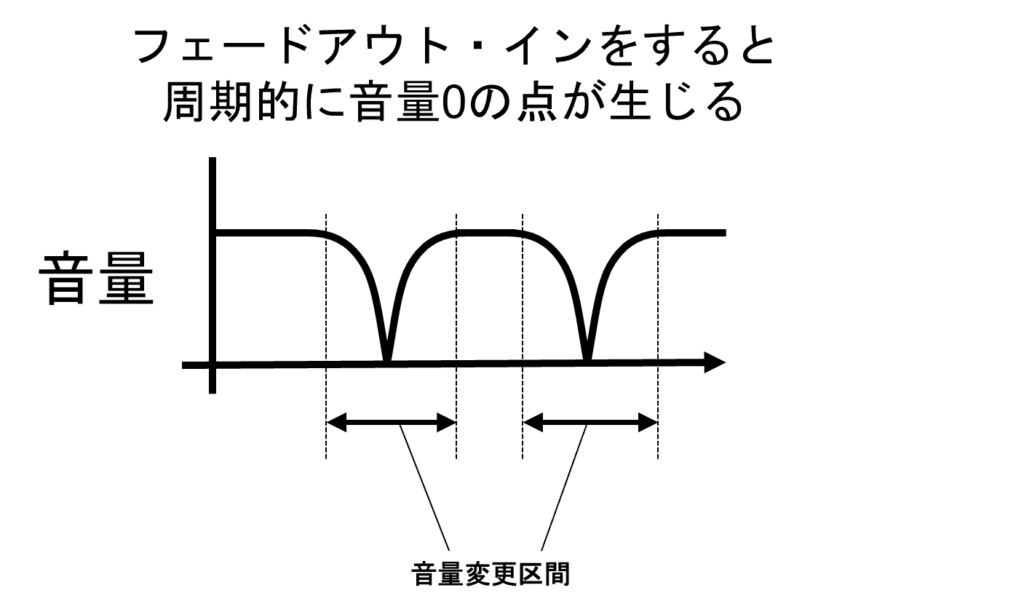
実は、上記の「継ぎ目対策あり」のサンプルではもう一工夫加えています。ここまでに述べた処理を行うと周期的に音量が0となる区間が生じるため、同じ音がずっと鳴っているような信号を入力とした場合に、音量が0となる瞬間がちょっと目立ってしまいます。例えば「ポーー」とずっと鳴っている正弦波の信号を入力とすると「ポポポポポ…」という風に、プツプツとしたノイズは入らないものの、若干トレモロ2のような効果が入ってしまいます。
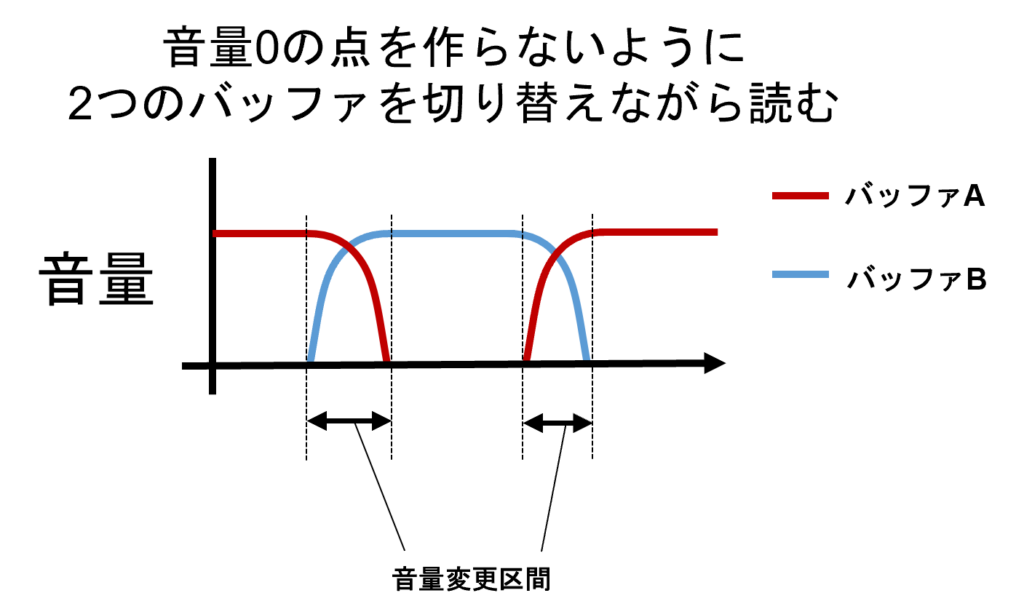
この現象への対策として、バッファを2つ用意する方法が考えられます。まず、読み出しタイミングをずらした2つのバッファA,Bを用意します。最初はバッファAからデータを読み出していき、バッファAが「継ぎ目」に差し掛かり音量を下げていく(フェードアウト)タイミングに差し掛かったところで、同時にバッファBからデータを読み出していくようにします。バッファAとBの間の読み出しタイミングのずらし量を十分大きく取っておけば、このとき、バッファBから読み出されるデータは「継ぎ目」ではない場所になります。しかしいきなりバッファBのデータを読み出し始めるとバッファAとBの切り替えポイントが「継ぎ目」になってしまうので、バッファAとは逆に、徐々に音量を上げていく(フェードイン)ようにします。このように、バッファAのフェードアウトとバッファBのフェードインをオーバーラップして行う(クロスフェード)ことで、音量が0になる区間を防ぎながら、データの継ぎ目を目立たなくすることができます。
PCのようにメモリが十分にある環境であればこのまま、2つのバッファを用意して処理を実装すればよいのですが、音声波形の周期性を利用してさらにメモリを節約することもできます。その場合バッファA,Bを用意するのではなく、一つのバッファに対して読み出しポイントAとBを用意し、それぞれの読み出しポイントをずらしておきます。典型的には読み出しポイントAからみて、ちょうどバッファの半分のサイズだけずらした位置に読み出しポイントBを設定します。これまでも書いた通り、音声波形には周期性がありますから、うまくバッファのサイズを決めてやれば途中でちょっと古いサンプルを読み出し始めても、「それっぽく」聞こえてしまいます。先ほど示した「継ぎ目対策あり」のサンプルでは、クロスフェード処理に加えて、このテクニックも使用しています。
ESP32に処理を載せる

メガホンにボイスチェンジャーを内蔵するにあたり、処理を実装するハードウェアとして、以前製作したESP32とオーディオ用ADC/DACを1つにまとめた基板を使用しました。この基板は大半の部品をJLCPCBのPCBAで実装してもらい、手元に在庫がある部品のみ自前で実装しています。ESP32であれば、本体SRAMだけでも数百KBありますし、この基板で使っているESP32-WROVER-Eを使えば8MBの外付けPSRAMも使えるため、メモリがたくさん必要になりがちなオーディオエフェクトの実装でも安心です。
ボイスチェンジャーメガホンに実装したピッチシフトのアルゴリズムは、最初からESP32向けに実装するのではなく、ここまでに紹介した内容を一度PC上でPythonを使って実装しています。このPythonでの実装で、「継ぎ目」対策の処理などを検討し大枠が固まった後にESP32向けにC/C++で再実装しています。この再実装の際に、CPUの負荷を下げるために以下のような手法を導入しています。ESP32のようにパワフルで、FPU3を搭載しているマイコンでは、これらの手法を導入しなくてもピッチシフト処理くらいであれば難なく動かすことができると思いますが、他の処理も同時に動かす際には役立つでしょう。
固定小数点演算化
「継ぎ目」対策のクロスフェード処理や、バッファの読み出し速度の変更処理などでは、小数を扱う必要があります。前者では音量を下げるために、1.0, 0.9, 0.8…といったように、音声信号に係数をかけていきます。バッファの読み出し速度変更の場合、読み出し速度を0.9倍にしたり、1.1倍にしたりと、ここでも小数が出てきます。
PythonやC/C++などで、言語に組み込みの小数型を使うと浮動小数点数として取り扱われます。通常のPCに使用されているCPUではFPUが搭載されているため、浮動小数点数を素直に取り扱うことができますが、FPUが搭載されていないことの多いマイコンでは浮動小数点数を使った処理はかなりの負荷になります。ESP32の場合、FPUが搭載されていますが、FPUを使わない整数演算の方が高速であることが知られています。(なお、整数演算の方が高速なのは、ESP32に限らず一般的なCPUに言えることです。)
そこで、整数演算を活用して小数値を扱う、固定小数点演算というアプローチを使って処理の高速化を図ります。固定小数点演算は整数値を小数とみなして演算する手法です。
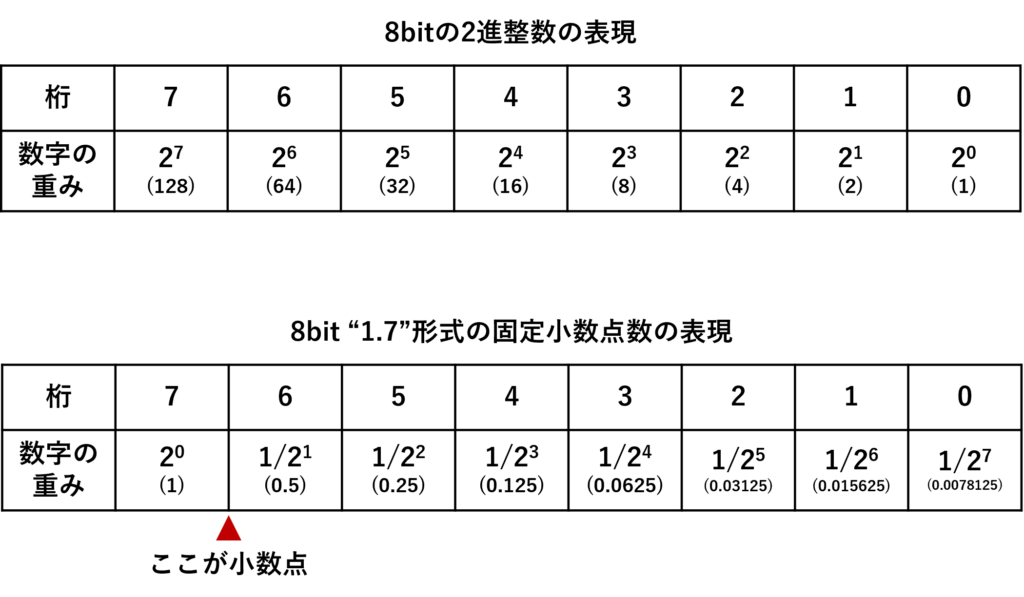
上に通常の8bit符号なし整数と、8bitの”1.7″形式の固定小数点数の表現例を示します。1.7形式というのは、整数部が1bit、小数部が7bitの固定小数点数、という意味です。整数の場合、最下桁(0桁目)が2の0乗、すなわち1の重み、1桁目が2の1乗=2の重み…といったように重みを持ちます。一方で、1.7形式では、最上桁(7桁目)が1の重みで、そこから1/2、1/(2^2)=1/4の重み…というように、各桁が小数の重みを持ちます。たとえば、2進数表記で”1010 0000″は2進整数表現だと、128+32=160となりますが、1.7形式の固定小数点数だと、1+0.25=1.25となります。
固定小数点数で小数を表現すると、形式が同じ(小数点の位置が同じ)固定小数点数どうしでは加減算を整数と同じやり方で行えるというメリットがあります。乗除算については、計算結果の小数点の位置がずれる(例えば1.7形式の固定小数点数どうしを乗算すると、2.14形式の固定小数点数が得られます)のを補正してやる必要がありますが、それ以外は整数演算と同様です。さらに、小数点の位置補正は、多くのCPUでは高速に実行できるシフト演算で実現できます。昨今のPCで一般的な浮動小数点数では、四則演算の実行にこれよりも多くの手順がかかります。4
ESP32での実装では、クロスフェード処理のところで15.16形式(+符号で1bitで計32bit、実際は1.0~0の範囲しか使っていないのでオーバースペックですが…)、バッファ読み出し速度の調整のところで11.16形式(32bit符号なし整数として実装していますが、バッファサイズとの兼ね合いで、整数部は11bitしか使っていません)の固定小数点数表現を使っています。
クロスフェード用減衰カーブのテーブル化
Pythonでの実装ではクロスフェード処理の減衰カーブはNumPyのsin/cos関数を呼び出して生成していますが、この手の数学関数も一般的にマイコンにとっては負荷が高い処理となります。そこで、ESP32向けの実装では、事前に使用する範囲のsin/cos関数の値を計算し、配列としてあらかじめ持っておいた値を参照するようにしています。また、先に述べた固定小数点数表現にあらかじめ変換して配列に保持しています。
その他
その他、演算高速化の工夫ではありませんが、PC上での実装に加えてESP32向けの実装では以下のような機能を実装しています。
- ESP32のGPIOの状態に応じてピッチの変更量を変える機能
- 簡易エコー(いまいちだったので今は使っていませんがコードは残っています)
- バッファー出力値の線形補間(あまり効果はない気がしますが…)
今回のまとめ
今回はボイスチェンジャーメガホンで使用しているリサンプリングによるピッチシフト処理と、それをESP32に実装するための工夫について説明しました。
なお、この記事の公開に合わせて、ボイスチェンジャーメガホンのソースコードはGitHubに置いておきました。ついでに、上記の基板で使っているTIのCODEC(ADC/DAC)チップであるTLV320AIC3204のドライバも公開しました。
次回はボイスチェンジャーメガホンのハードウェア構成について紹介します。お楽しみに!
参考文献
なお、今回のリサンプリングによるピッチシフトの実装では、以下の資料を参考にしています。
- TN: Using the Low Cost, High Performance ADSP21065L DSP for Digital Audio Applications (Rev. 1)
- タイムストレッチ、ピッチシフトのアルゴリズム