お知らせ:この記事はJLCPCBの提供でお送りしています。
みなさんこんにちは。今回は今年の6月に開催されたNT金沢2022で展示したボイスチェンジャーメガホンの中身について、原理編・ソフトウェア編・ハードウェア編の3回に分けて紹介したいと思います。実際にNT金沢2022で遊んでいただいた様子は「NT金沢2022に行ってきました」をご覧ください。
作ったのはこんなもの
買ったばかりのメガホンの音がおかしい pic.twitter.com/1xIUvaauzG
— JA1TYE/Ryota Suzuki (@JA1TYE) January 30, 2022
ボイスチェンジャーメガホンは読んで字のごとく、ボイスチェンジャーを内蔵したメガホンです。テレビ番組などで「プライバシー保護のため音声を一部加工しています」というようなキャプションとセットで適用されていることのある、あの妙に高い声や低い声を出すことができます。Twitterに最初に投稿したときは地声の音程を上げて高い声にする機能だけでしたが、NT金沢に持って行く際には低い声にもできるように機能追加をしていました。
ボイスチェンジャーの作り方いろいろ
さて、「ボイスチェンジャー」として使われるエフェクトはいくつか存在します。今回実装したものも含め、まずはそれぞれのエフェクトについて簡単に説明したいと思います。
なお、せっかくなのでこの後紹介するリングモジュレーターと2種類のピッチシフトの手法については、サンプル音声を用意しました。比較用のオリジナル音声は以下です。各手法のサンプル音声はそれぞれのセクションの末尾に置いてあります。
リングモジュレーター
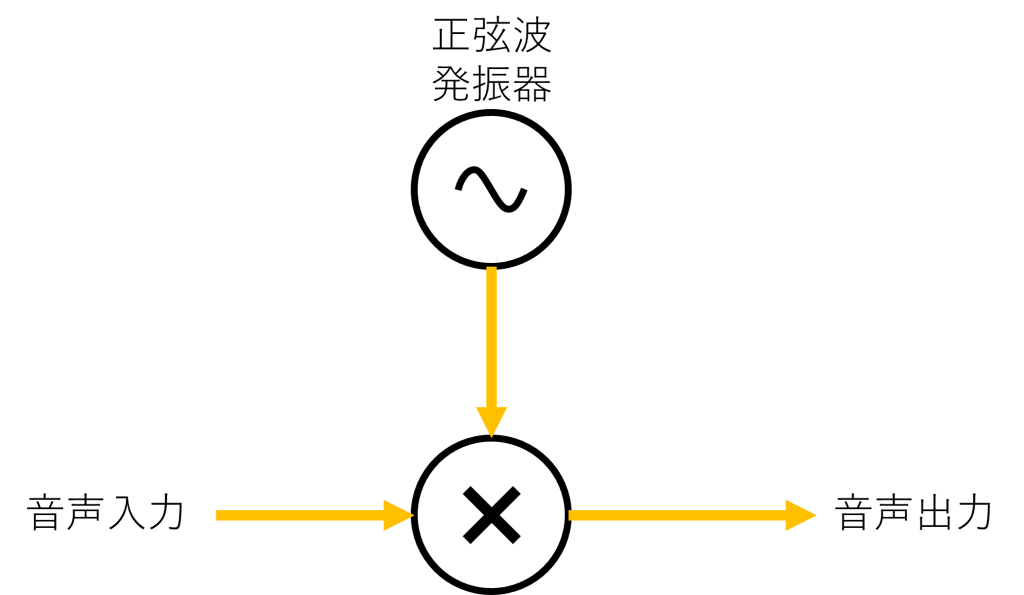
リングモジュレーターはボイスチェンジャーとして使われるエフェクトとしては最も原始的な手法ではないかと思います。リングモジュレーターは2つの入力の乗算結果を出力する処理によって実現されます。一般的に、音声に限らずあらゆる信号は、様々な周波数・位相・振幅の正弦波の集まりに分解することができます。通常の音声信号に別の正弦波を掛けてやると、三角関数の積和公式から、元の音声信号の中に含まれる各々の正弦波と、掛けた正弦波の周波数の和と差の周波数をもつ正弦波が出てくることが分かります。結果として、元の声よりも少し高い声と、低い声が混じったような音声を作ることができます。ちなみにこのタイプのボイスチェンジャーは以前製作しています。
ピッチシフト
次に紹介するピッチシフトは、おそらく最も一般的に「ボイスチェンジャー」としてイメージされるエフェクトだと思います。ピッチシフトはその名の通り、入力された音声の音程(ピッチ)を、できるだけその他の音質などの要素を損なわずに変更するエフェクトです。ここではピッチシフトの実現方法として、リサンプリングとフェーズボコーダーの2種類を紹介します。
リサンプリング
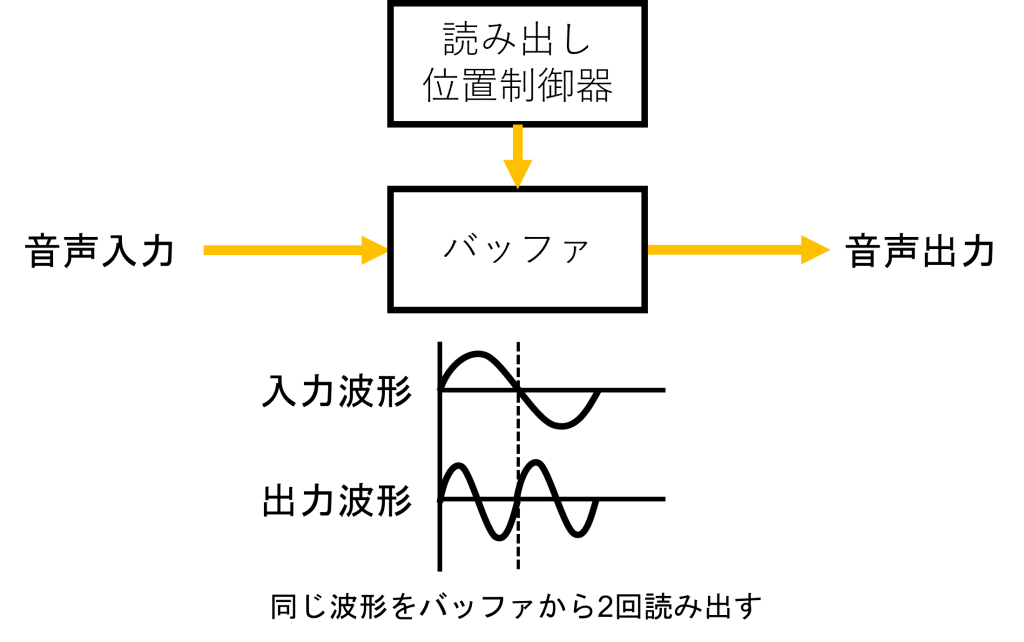
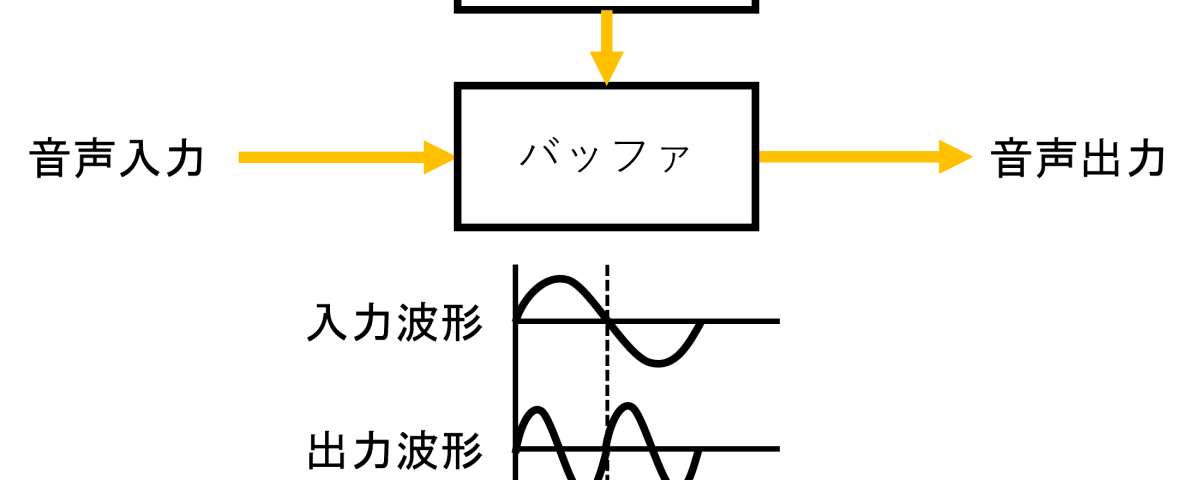
リサンプリングは音声入力データを適宜読み飛ばしたり、複数回読んだりすることでピッチシフトを実現します。上の図のように、音程を2倍にしたい場合はまず、バッファに格納した音声入力データを、入力時の2倍の速度で読み出します。そうすると音声の周波数も2倍になります。しかし、そのままだと当然ながら音の再生時間は1/2になってしまうので、再生時間の帳尻を合わすために、バッファ内の波形を2回繰り返して読み出します。このように、うまく波形をつぎはぎして、音程を上げたり、逆にバッファに格納した音声入力データをゆっくり読みだすことで、音程を下げたりするのがリサンプリングです。テレビ番組などで見かけるボイスチェンジャーのエフェクトでは、この手法が使われていることが多いのではないかと思います。
フェーズボコーダー

フェーズボコーダーはリサンプリングよりもよりよい音質を実現できるピッチシフト手法です。先ほどリングモジュレーターのセクションで説明したように、音声信号は様々な周波数の正弦波の集まりとしても表現できます。フェーズボコーダーは、音声入力をFFT1にかけることで、まず音声信号を正弦波の集まりとしての表現(周波数領域での表現)に変換します。
音程の違いは周波数の違いですから、周波数領域の表現において、元の音声信号が持つ周波数成分をより低い周波数成分とみなすようにすれば音程が低く、逆に高い周波数成分とみなせば音程が高くなります。しかし、周波数領域での表現のままでは人間が聞き取れる音声にはならないので、このようにしてそれぞれの周波数成分を変更した後で、逆FFTを行うことで時間領域の(我々が聞き取れる)信号に戻します。原理だけ書くとシンプルですが、単純にFFTしただけでは細かい周波数や位相の情報が失われしまうので、そこを補正する手法がフェーズボコーダーで工夫されるポイントとなります。音楽制作用のソフトのピッチ補正機能は、フェーズボコーダーで実装されていることが多いようです。
(チャネル)ボコーダー

ボコーダーは先ほど紹介したフェーズボコーダーと名前も構成も似ています。音声信号の特徴量を抽出して、あとから元に戻すというアプローチが同じであることから、どちらもボコーダー(VOice CODER)と呼ばれています。エフェクトとしては「ボコーダー」というと、ここで紹介するものを指すことが多いかと思います。フェーズボコーダーと明確に区別したいときはチャネルボコーダーと呼ばれます。
チャネルボコーダーでは、音声入力の他にキャリア入力というもう一つの入力が必要です。それぞれの入力信号はFFTなどにより、ある程度の幅を持った周波数帯ごとの成分に分解されます。その後、周波数帯ごとの成分に分解された音声信号は、それぞれの振幅の情報に変換されます。この振幅の情報を、キャリア入力の対応する周波数帯の成分に掛け合わせ、最後に逆FFTで時間領域の信号に戻してやると、キャリア入力の信号の特徴と音声入力の信号の特徴の両方を併せ持った信号が得られます。この時、FFTの刻み幅(周波数成分をどの程度の幅で切り出すか)を工夫してやると、音程はキャリア入力の音程のままで、信号全体としての周波数分布(たとえば低い周波数の成分は少なく、高い周波数の成分は多い…など)は音声入力の信号の特徴が反映された信号ができます。簡単に言えば、音声入力の特徴量をキャリア入力に映しこむことができる、という感じでしょうか。ボコーダーの場合、先ほど書いたように音程はキャリア入力の音程がそのまま反映されるため、抑揚がなくなったようなロボットボイスを作るときに使われることが多いかと思います。
なお、ボコーダーについても過去に実装したことがあります。
AIによる声質変換
その他、最近では人の声の特徴を学習させたニューラルネットワークを使って、ある人の声を別の人の声に変換させるような技術もたくさんあるかと思います。
今回のまとめ
今回はボイスチェンジャーメガホンと、ボイスチェンジャーエフェクトとして使われる各種のエフェクトの原理について紹介しました。次回、ソフトウェア編では、今回紹介したボイスチェンジャーエフェクトのうち、実際にボイスチェンジャーメガホンで採用した、リサンプリングによるピッチシフト処理の実装について紹介します。お楽しみに!